联邦学习:分布式机器学习下的数据隐私保护


1 算法简介
联邦学习(Federated Learning,FL),又名联合学习、联盟学习,是一种创新的机器学习框架。它是一种分布式机器学习方法,允许多个参与者在不共享原始数据的情况下共同训练模型。这种方法在保护数据隐私的同时,利用多方数据进行模型训练,适用于数据孤岛场景,使企业能够在保护用户隐私的同时,使用分散的数据源进行模型训练。
在人工智能的浪潮中,联邦学习以其独特的分布式学习机制,正在成为数据隐私保护与模型训练效率提升的桥梁。本文将探讨联邦学习的简介、原理以及应用,详细介绍这一前沿技术。
2 算法原理
联邦学习的工作原理基于去中心化的学习原则,旨在通过多个客户端的协作来训练全局模型,同时确保数据的隐私和安全。在这种框架下,各个参与方(如移动设备、浏览器或分布式服务器)利用本地的数据进行模型训练,将模型更新(如梯度或模型参数)发送给中央服务器,而不是发送原始数据。
我们把每个参与共同建模的企业称为参与方,根据多参与方之间数据分布的不同,把联邦学习分为三类:横向联邦学习、纵向联邦学习和联邦迁移学习。
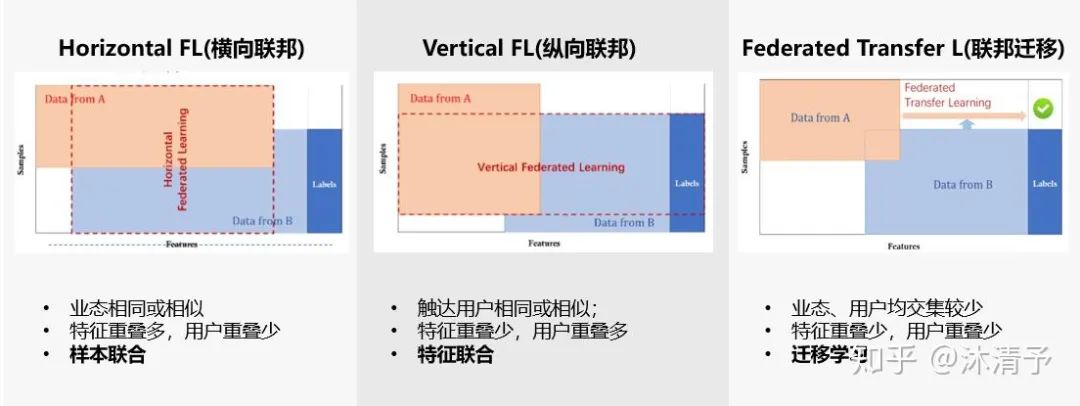
核心算法步骤:
(1)初始模型分发:中央服务器首先使用可用数据的子集训练一个初始的全局模型。然后,这个模型被分发到所有参与的客户端。
(2)本地训练:每个客户端使用其本地数据对接收到的模型进行训练。这个过程是在客户端设备上本地完成的,不需要将用户数据上传到服务器。
(3)模型更新传输:训练完成后,各个客户端将模型的更新(如权重和梯度)发送到中央服务器。这些更新是模型训练过程中的关键信息,用于更新全局模型。
(4)模型聚合:中央服务器接收来自各个客户端的模型更新,并通过聚合算法(如加权平均)将这些更新合并成一个新的全局模型。
(5)全局模型迭代更新:更新后的全局模型再次被分发回各个客户端进行下一轮的本地训练。这个过程可以迭代进行多次,直到模型达到预期的性能或收敛。
3 算法应用
联邦学习在各个行业有着广泛的应用前景,特别是在需要保护用户数据隐私的场景中。例如,在金融领域,联邦学习可以帮助银行和金融机构可以在不泄露客户数据的情况下,共同训练一个反欺诈模型来识别潜在的欺诈行为,保护了客户的隐私权益。在移动计算领域,联邦学习可以用于通过学习数百万用户的打字模式来提高预测文本模型的性能,从而优化其预测算法,无需访问用户的个人消息,提升了用户体验,也保护了用户的隐私安全。在医疗领域,联邦学习可以用于开发使用多个医院数据的预测模型,而无需共享患者的原始数据,不仅提高了模型的准确性和泛化能力,还保护了患者的隐私权益。
在中医药领域,联邦学习可用于数据隐私保护、疾病预测、个性化中医药推荐等方面。利用联邦学习可以整合多家医院或诊所的中医药数据,这些数据通常包括患者的诊断信息、用药记录、治疗效果等。通过联邦学习,可以在不泄露原始数据的前提下,实现跨机构的数据挖掘和疾病预测模型优化。例如,可以联合多家医院对用户的诊断数据信息,在不泄露用户隐私的前提下,提升某种疾病发病预测模型的效果。做到早识别、早预防。此外,利用联邦学习技术,可以整合不同机构的患者数据和中医药方剂数据,训练一个个性化的推荐系统,该系统可以根据患者的个体特征和病情情况,推荐适合的中医药方剂和治疗方法。联邦学习与中医药领域的结合也有助于增强患者对中医药研究的信任度,推动中医药研究的深入发展。
4 小结
联邦学习作为一种新兴的机器学习方法,正在快速发展并在多个领域展现出广阔的应用前景。其独特的分布式学习机制不仅打破了传统机器学习对数据集中化的依赖,还在数据隐私保护、模型训练效率提升以及资源节省方面展现出显著的优势。然而,联邦学习也面临一些挑战和限制。数据异构性、通信开销、安全性和复杂性等问题需要不断研究和解决。此外,随着技术的不断发展和应用场景的不断拓展,联邦学习还需要不断适应新的需求和挑战。
未来,随着对数据隐私的日益关注以及边缘生成数据量的不断增长,联邦学习有望在更多领域得到应用和推广。


| 文章 | 点赞 | 获赞 | 粉丝 | 关注 |
| 2786 | 434 | 184 | 147 | 44 |
- 联邦学习:分布式机器学习下的数据隐私保护
- 联邦学习(Federated Learning)概述
- AI将化身24小时在线的专属演讲教练 樊荣强的一次AI+演讲跨界探索
- 生成式AI对信息能进行价值判断和真假判断吗?
- 如何正确地向DeepSeek发问或者发指令?这六个核心要点必须掌握
- DeepSeek回答问题的时候,如何区分真实世界与文学创作的边界?
- DeepSeek会造假与说谎究竟是好事还是坏事?
- 让AI豆包点评演讲:如何快速地挣更多的钱?
- 少跟妈妈说难过的事
- 努力挣钱吧,兄弟
- 治愈你的焦虑症:著名心理医生有一段极为精辟的言论
- 樊荣强元写作理论在新媒体文章创作中的运用
- 一张图拆解穷字,教你如何摆脱贫穷
- 从“灵感依赖”到“结构化思维”的转变——论元写作对写作底层逻辑的重构
- 100个常用的DeepSeek提示词
- 策划“占领华尔街”运动后,他写了本书批判《人类新史》
- 莫以一时之瑕,以为DeepSeek永远是“幼儿园水平”
- 掌握元思维,中学生写作文变得好简单
- 公务员面试宝典!《神经——元思维:问与答的思考及表达智慧》读后感
- 大学生写论文从此不难!《神经——元思维:问与答的思考及表达智慧》读后感
- 机关秘书必读:樊荣强元思维揭秘高效工作背后的思考公式
- 品宣文案就这么写:《神经——元思维:问与答的思考及表达智慧》深度读后感
- 写方案就这么简单!《神经——元思维:问与答的思考及表达智慧》燃爆读后感
- 文案狗秘籍:《神经——元思维:问与答的思考及表达智慧》炸裂读后感
- 樊荣强“元思维”概念,强调思考与表达的基础是“提问-回答”的循环
- 探索写作新境界:樊荣强《元写作》开启高效写作之门
- 关于元思维理论:樊荣强对DeepSeek的深度思考与批判的反思
- 恩格斯的资本批判及其特征
- DeepSeek对樊荣强元思维理论的批判性评价
- 真理在喧哗中沉默:一场关于认知的黑色幽默

- 联邦学习(Federated Learning)概述
- AI将化身24小时在线的专属演讲教练 樊荣强的一次AI+演讲跨界探索
- 生成式AI对信息能进行价值判断和真假判断吗?
- 如何正确地向DeepSeek发问或者发指令?这六个核心要点必须掌握
- DeepSeek回答问题的时候,如何区分真实世界与文学创作的边界?
- DeepSeek会造假与说谎究竟是好事还是坏事?
- 让AI豆包点评演讲:如何快速地挣更多的钱?
- 少跟妈妈说难过的事
- 努力挣钱吧,兄弟
- 治愈你的焦虑症:著名心理医生有一段极为精辟的言论
- 樊荣强元写作理论在新媒体文章创作中的运用
- 一张图拆解穷字,教你如何摆脱贫穷
- 从“灵感依赖”到“结构化思维”的转变——论元写作对写作底层逻辑的重构
- 100个常用的DeepSeek提示词
- 策划“占领华尔街”运动后,他写了本书批判《人类新史》
- 樊荣强乱弹《论语》八佾篇20:乐而不淫
- DeepSeek:评樊荣强《三的智慧:思考与演讲的75个经典分析工具》
- DeepSeek称赞樊荣强《三的智慧:思考与演讲的75个经典分析工具》
- DeepSeek介绍樊荣强的元思维的定义、核心及例子
- 成大事必知的10个社会潜规则 撕开社会面具,这10条规则你必须懂
- 《哪吒2》根本就不是一部电影,就是一部家庭教育大典
- DeepSeek:评樊荣强《三的智慧:思考与演讲的75个经典分析工具》
- 饺子与豆包对话:樊荣强元思维及其运用举例
- 与豆包对话:怎么用樊荣强元思维理论提升演讲表达能力
- 与AI豆包对话:樊荣强的元写作让孩子不管什么作文题目都能应对自如
- 樊荣强的《元写作》这本书究竟有什么独特的价值?
- 诺基亚最臭的一步棋就是打死不向安卓低头
- 运用元写作理论写文章,有哪些常见错误要避免?
- DeepSeek横空出世:AI三大超能力引爆全球震撼
- 元写作思维不仅是一种写作方法论,更是一种认知升级工具
