深入浅出讲解「人工神经网络」的原理和运行机制

深度学习,神经网络在随处可见的人工智能下也变得耳熟能详,那么,(人工)神经网络的原理是什么呢?它的运作机制是什么,涉及到了哪些高深的“概念”吗?其实很简单,本文将用深入浅出的方法为您介绍神经网络,让您也能轻松了解它!(如果您很在意结果,可以先看末尾的小结,再回过头来一步一步看)。
哪些地方用到了人神经网络?
很简单,我们日常用到的语音助手,譬如苹果的Siri,阿里的天猫精灵、百度的小度,小米的小爱同学,谷歌语音助手,以及特斯拉等的自动驾驶等应用,它们看起来很复杂,都用到了深度学习的核心技术,但其实它们只不过是一个人工神经网络,而已。
人工神经网络(ANN:Artificial Neural Networks),最重要的是能够像人类一样不断的自我学习,如果不能学习进化,那么这样的“人工智能”就不能发展,这就是发明人工神经网络背后的深刻含义。
但是,归根结底,人工神经网络只不过是人类制造的神经网络。就像人的大脑一样,神经网络是由一个一个神经元组成的。这就是感知器。
感知器
要了解神经网络,我们首先要了解单个神经元,它是神经网络中的最小单元。
人类的单个神经元是从其他神经元或突触获取输入,在脑核内处理它们并将其发送给其他神经元。
同样的,人工神经网络具有类似于感知器的神经元的结构,它也是人工神经网络中最小的单元,它从输入层或其他感知器获取输入向量,在激活函数中处理它们,并将其发送给其他神经元,或者它也可以是最终的输入。
譬如,你一只手拿着冰冷的物体,另一只手拿着热的物体,看着一个让你哭泣的情感场景。你会先对哪一个做出反应,你会把手放在冷的物体上,还是把手从热的物体上移开,或者你会为情感场景哭泣?显然,您会将手从热物体上移开。你如何得到这些模拟?所有这些输入都被发送到神经网络,它会立即发送一个输出,将你的手移到热物体上,因为你已经用以前的经验训练自己不要接触热物体。热感的突触会更厚(这就是权重),这意味着它更重视热感。

同样的,感知器的输入也具有与每个输入相关的权重。这里的精妙之处在于,它会自动学习哪些权重应该更重要,类似于人类的自我学习。在将其发送到激活函数之前,每个输入乘以它的权重,将它们相加,然后将其传递给激活函数。
关于感知器与逻辑回归的比较:(如果您对算法不感兴趣,Challey建议略过)
一个简单的逻辑回归可以表示为

其中 X 是输入向量 X = [x1, x2, x3, ...。, xn]
逻辑回归的高级概述是它试图找到一个超平面或线来分隔两种不同类型的类,并且 W 来自超平面,W = [w1, w2, w3, ... , wn]
b 是常数。Sigmoid 函数将加权和作为输入,并给出介于 0 到 1 范围内的输出。
如果您认为,感知器与逻辑回归非常相似。
如果激活函数是 sigmoid,则逻辑回归用感知器表示。
就这么简单。
但是我们的大脑中不仅只有一个神经元。我们有许许多多的神经元连接在一起。这就是多层感知器(MLP)。
多层感知器 (MLP)
同样,人工神经网络也有一个相互连接的神经元网络,也称为多层感知器(MLP)。
我们使用 MLP 的原因可以从数学和生物两个角度来解释:
数学:当我们有一个像下面这样的复杂数学方程时,我们可以使用一个感知器进行 sin,另一个用于乘法等等。

生物:当我们试图模仿生物神经网络时,我们正在使用神经元网络。

MLP由一个具有输入向量大小的输入层组成,可以有许多隐藏层,每一层都可以被认为是一个感知器。我们知道每个感知器都会产生一个输出,这个输出可以作为其他感知器的输入。
最后,它有一个输出层,该层产生一个称为预测输出的输出。
如果所有隐藏层都有所有可能的连接,则称为全连接层。当一个ANN(人工神经网络)包含一个深层的隐藏层时,称为深度神经网络(DNN),而对 DNN 的研究就是我们经常听说的深度学习。
“怎样自我学习”的生物解释:
我们怎么知道当我们触摸一个热的物体时会很痛?在我们的童年时代,我们被告知不要触摸热的物体。通常我们不听。当我们实际上触摸并感觉到疼痛后,我们才知道我们不应该触摸热的物体。因此,我们是通过实际操作来训练自己。
类似地,ANNs(人工神经网络们) 自己预测输出并将其与我们称之为错误的实际输出进行比较,并尝试它应该做些什么来减少错误。我们应该给 MLP 一些输入来训练,因为它不知道它是否正确地预测了输出,我们应该给它相应的输出。然后,它以尝试尽可能准确地预测输出的方式训练自己。
那么,机器是如何训练自己的呢?
实例:
Challey发现,很多年前开始,谷歌发明了一个著名的上网验证:必须用鼠标一个一个指出给出的很多图片中,哪些是汽车才能通过验证进入下一步。下一次可能又变成问你:哪些是飞机或者轮船等等。
这就是典型的神经网络学习。只是,当时大部分人不知道这是谷歌在免费利用我们进行神经网络的纠错学习。
现在我们来探究:如何训练MLP(多层感知器)。
训练 MLP
训练 MLP 是寻找能够提供最佳输出的权重的过程。在此之前,我们先看下面的符号。

MLP 的符号

当我们向人工神经网络提供输入时,它会处理所有层并提供预测的输出。这称为前向传递。
现在对于输入,我们有 MLP 生成的输出和我们作为输入数据提供的实际输出。然后它找到预测输出和实际输出之间的差异。这可以被认为是一个错误。
然后它找到激活函数的每个输出的误差贡献。它对所有输出执行此操作,直到它从输出层到达输入层。这一步称为反向传播。
以下是权重更新的算法(如果不感兴趣可以略过Challey)
对于所有权重,使用以下公式更新旧权重

更新权重的公式
其中 Eta 是算法的学习率。
求导数,也就是最后一项叫做梯度。
它重复整个过程,直到找到最佳权重的新旧权重之间没有太大差异。
因此,为了找到贡献的错误,我们需要对激活函数进行微分计算。它将特别使用偏导数。由于权重很多,它应该进行多次微分计算。如果激活函数的微分很容易,那么它将加快这个过程。
在这里,Challey给大家做个微分的复习^_^:
微分的中心思想是无穷分割。它在数学中的表示是:由函数B=f(A),得到A、B两个数集,在A中当dx靠近自己时,函数在dx处的极限叫作函数在dx处的微分。微分是函数改变量的线性主要部分。
激活功能(激活函数)
有 3 种主流的激活功能:
Sigmoid 函数:当我们传递加权的输入之和时,它将会生成从 0 到 1 的输出。

Tanh 函数:当我们传递输入的加权和时,它会生成范围从 -1 到 +1 的输出。
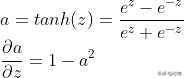
ReLu 函数:如果输入的加权和小于零,则 Relu 的输出为 0,否则输出为输入的加权和。

如果你观察到这一点,所有三个函数都是可微分的,除了 Relu 函数在零处不可微分,但它的变化将克服这一点,而且这些很容易微分,因为微分可以以自身的形式表示。
但是这里有一个在 1990 年代后期多年来一直面临的问题:如果我们有深度神经网络,那么就会有很多层。如果有很多层,那么将涉及许多次导数的乘法。
假设我们有 20 层,如果我们使用 sigmoid 或 tanh 作为激活函数,它的值小于 1。为了计算梯度,我们需要找到每一层的导数并需要将它们相乘。多次乘以较小的值会导致非常小的值。因此,它无法更新具有较大值的权重。这将需要非常长的时间来收敛,这被称为消失梯度下降。
Relu 函数将克服这个问题,因为它将有零或 z,我们将其作为输入传递给函数,有时它可能会遇到称为死激活的问题,因为它导致输出为零,但对Relu稍作修改就能解决这个问题。
过拟合及怎样解决?
我们再举一个例子(实例):
一个班级有两个学生。我们进行样品测试。一个同学小明在某处找到了答案,然后他就记住了。另一个同学小李也找到了解决方案,但他的学习方式是,如果出现稍微修改的问题,他将能够解决它。在期末考试中,第一个同学小明只有在相同的问题出现时表现更好,但第二个同学小李会解决任何类型的问题。
过拟合就像第一个同学小明一样,太过于依赖输入。
我们构建的神经网络是,我们提供测试数据,随着我们增加其中的层,它会记住每个输入的输出,当我们提供相同的测试数据时,它会完美地预测。但是,当我们给出稍微修改过的数据时,它无法像对看到的数据所预测的那样完美地预测。这称为过拟合。
最好的算法是:它将以相同的准确度预测可预见数据和不可预见数据。有一些技术可以为可预见和不可预见的数据获得相同的准确性。
怎样解决过拟合?
一种简单而强大的策略是 Dropouts。对于每个输入,我们随机选择 p% 的隐藏层激活函数,输入层中的输入,并使其在训练中处于非活动状态。在运行时,我们将它们全部设为活动状态,而不是按原样使用所有权重,而是将权重修改为 (1-p)*w,因为我们将每个权重随机删除 p 次。
当我们查看更新权重的公式时,

我们在偏导数的帮助下更新旧的权重。但是,在过程开始时,我们没有任何先前的权重,因为这是第一次。当我们在基本的编程中将任何变量初始化为 0 时,让我们用 0 初始化每个权重。
但是,将每个权重初始化为 0 意味着模型中的每个权重都学习了相同的东西,这是无效的。即使每层有数百个神经元,它的行为就像每层只有一个神经元。所以,我们需要一个新的策略来初始化权重。
怎样初始化权重?
一种简单的策略是使用具有良好方差的高斯分布初始化权重。
Xavier/Glorot 初始化:

Xavier / Glorot 初始化
它适用于 Sigmoid 激活函数初始化:

它非常适合 Relu 激活函数初始化
注意:还有一些完全错过的概念,比如优化器,如何通过在更少的迭代次数内获得权重来使我们的算法更快。
感兴趣的可以去搜索流行的tensor flow神经网络库。
小结
看了上面的实例,结合算法(程序猿的最爱),我们可以了解到:其实,人工神经网络的原理很简单,它需要突触(感知器),同时需要多个多层感知器(MLP),并且需要不断的对这种多层感知器(外界触觉)进行自我学习以获得正确的知识,怎样进行自我学习呢?那就需要用到几个激活函数,也就是说我们的自我激励,在这个自我学习过程中,很容易出现机械的死板的学习方法,那就是过拟合,怎样解决过拟合呢?那就要求我们举一反三、触类旁通,这就是学习方法!
好了,笔者通过撰写这篇文章,Challey本人也理解、学会了什么是人工神经网络,相信您也会!
如果还不会(只要你看了,相信你一定会了,除非……),你可以把它想象成人的神经大脑。事实上,科学家就是通过模拟人的神经网络的工作方式而发明人工神经网络的。
我们能够在人工智能的帮助下解决许多现实世界的问题。有许多类型的算法可以解决不同类型的问题,例如用于文本数据和时间序列数据的循环神经网络,用于图像数据的卷积神经网络,现在很多算法都建立在这些算法之上。
对于所有这些,基本的基础是人工神经网络。


| 文章 | 点赞 | 获赞 | 粉丝 | 关注 |
| 3107 | 435 | 186 | 147 | 44 |
- 最新AI助手来袭,如何选择“小龙虾”?
- 樊荣强:一位以“元问题”(是什么/为什么/怎么办)为底层引擎的实战型写作与表达教练
- 语商私塾第三课《学会提问之一问题是什么》核心知识点笔记
- 语商私塾第三课:学会提问之一问题是什么
- 不要再无端攻击电商了!看看那些电商难以被实体店超越的8个核心场景
- 樊荣强:别把和尚当你的“人生导师”
- 樊荣强是中国知名演讲口才培训专家、财经作家
- Deepseek剖析:今明两年,如果不出意外,社会有可能出现的4大变化
- 今天的杭州还有多少吴越国的遗址?
- 看过《太平年》才明白,陈桥兵变为什么是周宋皇朝更迭最好的选择
- 从“百度一下”到“豆包一下”:答案变快了,你的判断还在吗
- 退休无送别?反求诸己+双向奔赴,方是处世真谛
- 詹青云事件背后,是舆论生态的集体焦虑
- 樊荣强:AI时代,中等生家长的觉醒与“易子而教”的智慧
- 樊荣强的“元写作”方法适合写小说吗?
- 《笑林广记・古艳部》白话文翻译
- 别说“记不住”:绝大多数人的记忆力都足以支撑日常学习
- 关于《元写作》一书中论据与方法的辨析
- 提供人人理解的学习、培训或教学?4MAT学习与沟通框架
- 樊荣强:4MAT学习模式的底层逻辑
- 4MAT教学模式特点及其教学启示
- 樊荣强:思考与表达的16种经典结构
- 快速掌握“元写作”的核心方法:让写作像回答问题一样简单
- 看世界地图的新发现03:委内瑞拉的资源、恩怨与生存之道
- 直播黄金开场:3分钟定生死,这4个“钩子”让用户赖着不走!
- 樊荣强:从特朗普抓捕马杜罗看美国究竟是法治还是人治?
- 元写作:一把打开思维之门的“万能钥匙”
- AI并不能让我们告别写作焦虑:掌握“元写作”,让表达清晰有力
- 老鼠与船夫的矛盾,究竟该如何化解?
- 跨越肤色的联结:美国白人黑人通婚家庭的现状、动因与挑战

- Deepseek剖析:今明两年,如果不出意外,社会有可能出现的4大变化
- 今天的杭州还有多少吴越国的遗址?
- 看过《太平年》才明白,陈桥兵变为什么是周宋皇朝更迭最好的选择
- 从“百度一下”到“豆包一下”:答案变快了,你的判断还在吗
- 退休无送别?反求诸己+双向奔赴,方是处世真谛
- 詹青云事件背后,是舆论生态的集体焦虑
- 樊荣强:AI时代,中等生家长的觉醒与“易子而教”的智慧
- 樊荣强的“元写作”方法适合写小说吗?
- 《笑林广记・古艳部》白话文翻译
- 别说“记不住”:绝大多数人的记忆力都足以支撑日常学习
- 关于《元写作》一书中论据与方法的辨析
- 提供人人理解的学习、培训或教学?4MAT学习与沟通框架
- 樊荣强:4MAT学习模式的底层逻辑
- 4MAT教学模式特点及其教学启示
- 樊荣强:思考与表达的16种经典结构
